
Trong bài viết này, chúng tôi sẽ giúp bạn tìm hiểu cách các công cụ tìm kiếm thu thập dữ liệu(Crawl Budget) trên web, cách xác định xem ngân sách thu thập dữ liệu có liên quan đến trang web của bạn hay không và cách tối ưu hóa ngân sách đó.

Ngân sách thu thập dữ liệu (crawl budget) là một khái niệm thường bị hiểu nhầm. Và thường được thảo luận trong cộng đồng SEO và Digital marketing.
Hầu hết mọi người nghĩ rằng đó là một thứ ma thuật nào đó mà bạn có thể sử dụng để “hack” theo cách của bạn để đạt được kết quả hàng đầu của Google.
Bất chấp tất cả nội dung được viết về cách công cụ tìm kiếm hoạt động nói chung. Và quy trình thu thập dữ liệu nói riêng. Có vẻ như các nhà tiếp thị và web admin vẫn còn bối rối về ý tưởng Crawl budget.
Vấn đề
Rõ ràng là do thiếu hiểu biết về các nguyên tắc cơ bản của công cụ tìm kiếm. Và cách thức hoạt động của quá trình tìm kiếm.
Hiện tượng này tạo ra sự nhầm lẫn, vì vậy thường dẫn đến cái mà các nhà kinh doanh gọi là “hội chứng đối tượng tỏa sáng ” (Shiny Object Syndrome). Nhưng về cơ bản ngụ ý rằng nếu không có hiểu biết về các nguyên tắc cơ bản, các nhà tiếp thị sẽ ít có khả năng phân biệt, do đó họ mù quáng làm theo lời khuyên của bất kỳ ai.
Giải pháp
Bài viết này sẽ làm sáng tỏ các nguyên tắc cơ bản về thu thập dữ liệu. Cũng như cách sử dụng chúng để xác định xem “ngân sách thu thập dữ liệu” có phải là điều bạn nên quan tâm hay không. Và đó có thực sự là điều quan trọng đối với doanh nghiệp / trang web của bạn hay không.
Nó bao gồm:
- Cách thức hoạt động của công cụ tìm kiếm .
- Thu thập dữ liệu(crawl) hoạt động như thế nào?
- Ngân sách thu thập dữ liệu là gì và nó hoạt động như thế nào?
- Cách theo dõi và tối ưu hóa nó.
- Lợi ích tương lai của Crawl.
Định nghĩa
Trước khi chúng ta tìm hiểu sâu hơn về khái niệm ngân sách thu thập dữ liệu. Cần phải hiểu cách thức hoạt động của và ý nghĩa của nó đối với các công cụ tìm kiếm.
Cách công cụ tìm kiếm hoạt động
Theo Google, 3 bước cơ bản mà công cụ tìm kiếm tạo kết quả từ các trang web:
- Crawling: Trình thu thập dữ liệu web truy cập các trang web có sẵn một cách công khai
- Indexing : Google phân tích nội dung của từng trang và lưu trữ thông tin mà nó tìm thấy.
- Serving : Khi người dùng nhập truy vấn, Google sẽ trình bày các câu trả lời phù hợp nhất từ chỉ mục của nó.
Nếu không thu thập dữ liệu, nội dung của bạn sẽ không được lập chỉ mục. Do đó nó sẽ không xuất hiện trên Google.
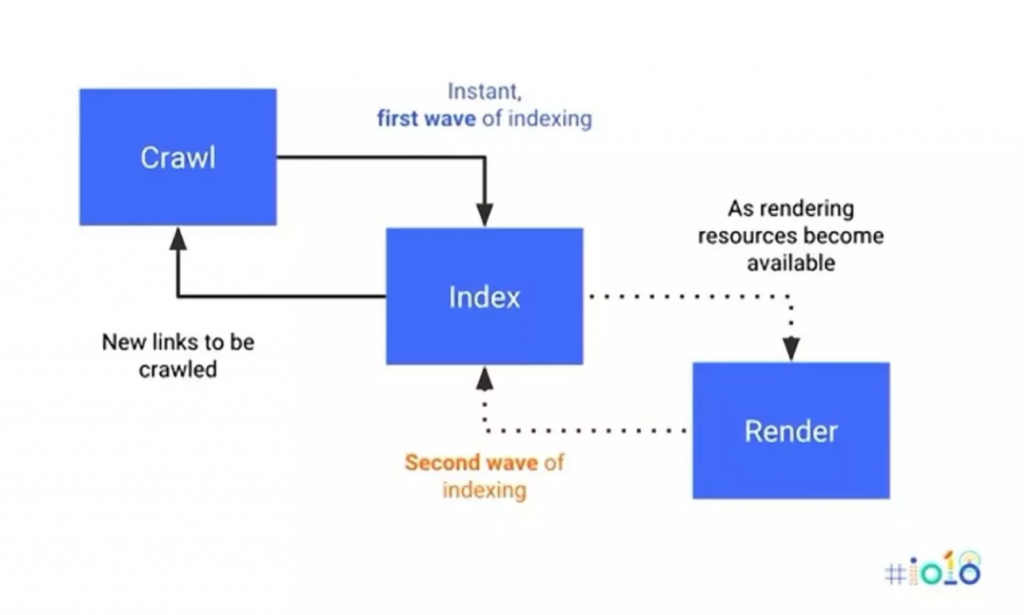
Các chi tiết cụ thể của quá trình thu thập dữ liệu
Google tuyên bố trên tài liệu của mình về việc thu thập dữ liệu và lập chỉ mục rằng:
“Quá trình thu thập dữ liệu bắt đầu với một danh sách các địa chỉ web. Crawl sử dụng các liên kết trên các trang đó để khám phá các trang khác. Phần mềm đặc biệt chú ý đến các trang web mới. Các thay đổi đối với các trang hiện có và các liên kết hỏng. ”.
Nó có ý nghĩa gì đối với SEO?
- Trình thu thập dữ liệu sử dụng liên kết trên các trang web để khám phá các trang khác. ( Cấu trúc internal link của trang web của bạn là rất quan trọng.)
- Trình thu thập dữ liệu ưu tiên các trang web mới. Các thay đổi đối với các trang hiện có và các liên kết đã hỏng.
- Quy trình tự động quyết định trang web nào sẽ thu thập thông tin, tần suất. Và số lượng trang mà Google sẽ tìm nạp.
- Quá trình thu thập dữ liệu bị ảnh hưởng bởi khả năng lưu trữ của bạn. (tài nguyên máy chủ và băng thông).
Như bạn có thể thấy, thu thập dữ liệu web là một quá trình phức tạp. Và tốn kém cho các công cụ tìm kiếm, xét về kích thước của web.
Nếu không có quy trình thu thập hiệu quả. Google sẽ không thể “sắp xếp dữ liệu và làm cho thông tin trở nên hữu ích. Và có thể truy cập được trên toàn cầu”.
Nhưng, làm thế nào để Google đảm bảo thu thập dữ liệu hiệu quả?
Bằng cách ưu tiên các trang và tài nguyên?
Điều đó gần như không thể và rất tốn kém cho Google để thu thập dữ liệu từng trang web.
Ngân sách Thu thập dữ liệu là gì?
Ngân sách thu thập dữ liệu là số trang mà trình thu thập thông tin đặt để thu thập thông tin trong một khoảng thời gian nhất định.
Khi ngân sách của bạn đã cạn kiệt. Trình thu thập dữ liệu web sẽ ngừng truy cập nội dung trang web của bạn và chuyển sang các trang web khác.
Nói chung, đây là bốn yếu tố chính mà Google sử dụng để phân bổ ngân sách thu thập dữ liệu:
- Kích thước trang web : Các trang web lớn hơn sẽ yêu cầu nhiều ngân sách thu thập dữ liệu hơn.
- Thiết lập máy chủ : Hiệu suất và thời gian tải trang web của bạn có thể ảnh hưởng đến lượng ngân sách được phân bổ cho nó.
- Tần suất cập nhật : Bạn có thường xuyên cập nhật nội dung của mình không? Google sẽ ưu tiên nội dung được cập nhật thường xuyên.
- Liên kết : Cấu trúc Internal Links và các liên kết hỏng.
Mặc dù đúng là các vấn đề liên quan đến thu thập dữ liệu có thể ngăn Google truy cập nội dung quan trọng nhất trên trang web của bạn, tuy nhiên, điều quan trọng là phải hiểu rằng tần suất thu thập dữ liệu không phải là một chỉ báo chất lượng.
Việc thu thập dữ liệu trang web của bạn thường xuyên hơn sẽ không giúp bạn xếp hạng tốt hơn.
Nếu nội dung của bạn không đạt tiêu chuẩn của người xem, nó sẽ không thu hút được người dùng mới.
Điều này sẽ không thay đổi bằng cách yêu cầu Googlebot thu thập dữ liệu trang web của bạn thường xuyên hơn.
Ngân sách Thu thập dữ liệu hoạt động như thế nào?
Hầu hết thông tin chúng tôi có về cách ngân sách thu thập dữ liệu hoạt động đến từ một bài báo trên Google’s Webmaster Central Blog .
Trong viết nhấn mạnh rằng:
- Ngân sách thu thập dữ liệu không phải là điều mà hầu hết các nhà xuất bản phải lo lắng.
- Nếu một trang web có ít hơn vài nghìn URL, phần lớn thời gian nó sẽ được thu thập dữ liệu một cách hiệu quả.
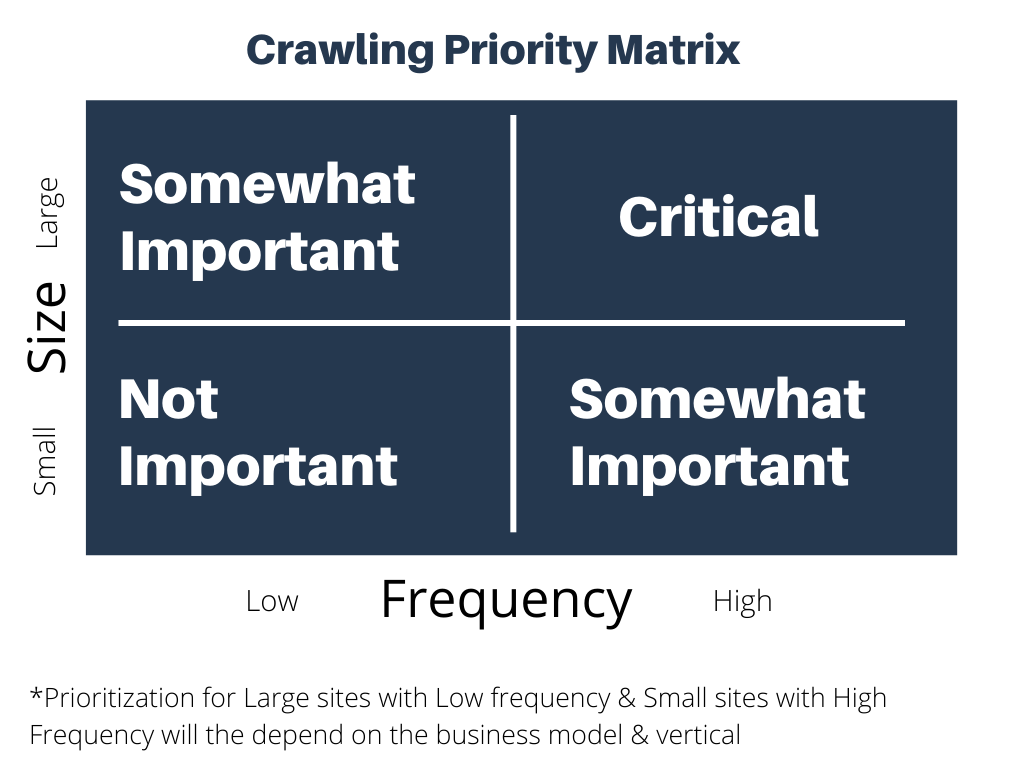
Dưới đây là các khái niệm chính bạn cần biết để hiểu rõ hơn về Crawl Budget.
Giới hạn tốc độ thu thập dữ liệu
Google biết rằng bot của họ có thể đặt ra các hạn chế nghiêm trọng đối với các trang web nếu không cẩn thận, vì vậy họ có các cơ chế kiểm soát để đảm bảo trình thu thập dữ liệu của họ chỉ truy cập một trang web thường xuyên và bền vững cho trang web đó.
Giới hạn tốc độ thu thập dữ liệu giúp Google xác định ngân sách thu thập dữ liệu cho một trang web.
Đây là cách nó hoạt động
- Googlebot sẽ thu thập thông tin một trang web.
- Bot sẽ đẩy máy chủ của trang web và xem nó phản hồi như thế nào.
- Sau đó, Googlebot sẽ giảm hoặc tăng giới hạn.
Chủ sở hữu trang web cũng có thể thay đổi giới hạn trong bảng điều khiển tìm kiếm của Google bằng cách mở trang Cài đặt tốc độ thu thập dữ liệu cho thuộc tính của bạn.

Nhu cầu thu thập dữ liệu
Googlebot cũng xem xét nhu cầu mà bất kỳ URL cụ thể nào nhận được từ chính chỉ mục để xác định mức độ hoạt động hay thụ động của nó.
Hai yếu tố đóng vai trò quan trọng trong việc xác định nhu cầu thu thập dữ liệu là:
- Mức độ phổ biến của URL: Các trang phổ biến sẽ được lập chỉ mục thường xuyên hơn những trang không được lập chỉ mục.
- Tính kiên cố: Hệ thống của Google sẽ ngăn chặn các URL cũ và sẽ có lợi cho nội dung cập nhật.
Google chủ yếu sử dụng các giới hạn tốc độ thu thập dữ liệu này. Và nhu cầu thu thập thông tin để xác định số lượng URL mà Googlebot có thể và muốn thu thập dữ liệu (ngân sách thu thập dữ liệu).
Các yếu tố ảnh hưởng đến ngân sách thu thập dữ liệu
Việc có một lượng đáng kể các URL có giá trị thấp trên trang web của bạn có thể ảnh hưởng tiêu cực đến khả năng thu thập dữ liệu của trang web.
Những thứ như infinite scrolling, duplicate content, và spam sẽ làm giảm đáng kể tiềm năng thu thập dữ liệu trang web của bạn.
Dưới đây là danh sách các yếu tố quan trọng sẽ ảnh hưởng đến ngân sách thu thập dữ liệu trang web của bạn.
Thiết lập Máy chủ & Lưu trữ
Google xem xét tính ổn định của từng trang web.
Googlebot sẽ không liên tục thu thập thông tin một trang web bị lỗi liên tục.
Điều hướng theo khía cạnh & Nhận dạng phiên
Nếu trang web của bạn có nhiều trang động, nó có thể gây ra sự cố với URL động cũng như khả năng truy cập.
Những vấn đề này sẽ ngăn Google lập chỉ mục nhiều trang hơn trên trang web của bạn.
Nội dung trùng lặp
Sao chép có thể là một vấn đề lớn vì nó không cung cấp giá trị cho người dùng Google.
Nội dung chất lượng thấp & Spam
Trình thu thập dữ liệu cũng sẽ giảm ngân sách của bạn nếu nó thấy rằng một phần đáng kể nội dung trên trang web của bạn có chất lượng thấp hoặc spam.
Kết xuất( Rendering)
Yêu cầu mạng được thực hiện trong quá trình hiển thị có thể được tính vào ngân sách thu thập dữ liệu của bạn.
Bạn không chắc kết xuất là gì?
Đây là quá trình điền các trang với dữ liệu từ các API và / hoặc cơ sở dữ liệu.
Nó giúp Google hiểu rõ hơn về bố cục và / hoặc cấu trúc trang web của bạn.
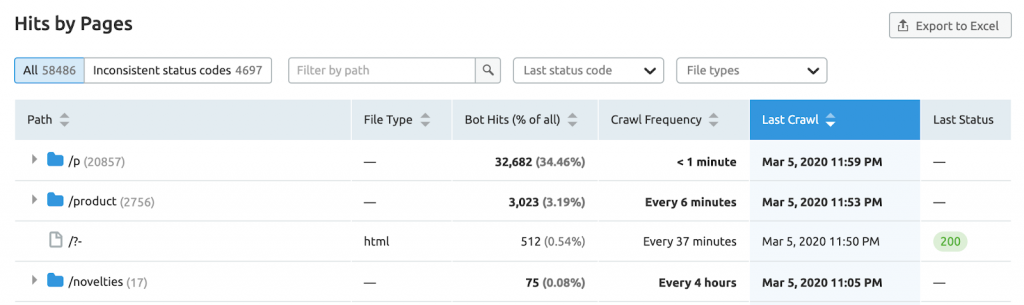
Cách theo dõi Ngân sách Thu thập dữ liệu
Có thể khó tìm ra và theo dõi ngân sách thu thập dữ liệu hiện tại của bạn là bao nhiêu vì Search Console mới đã ẩn hầu hết các báo cáo cũ.
Ngoài ra, ý tưởng về nhật ký máy chủ nghe có vẻ cực kỳ kỹ thuật đối với nhiều người
Dưới đây là tổng quan nhanh về hai cách phổ biến mà bạn có thể sử dụng để theo dõi ngân sách thu thập dữ liệu của mình.
Google Search Console
Bước 1: Vào Search Console > Legacy Tools and Reports > Crawl Stats
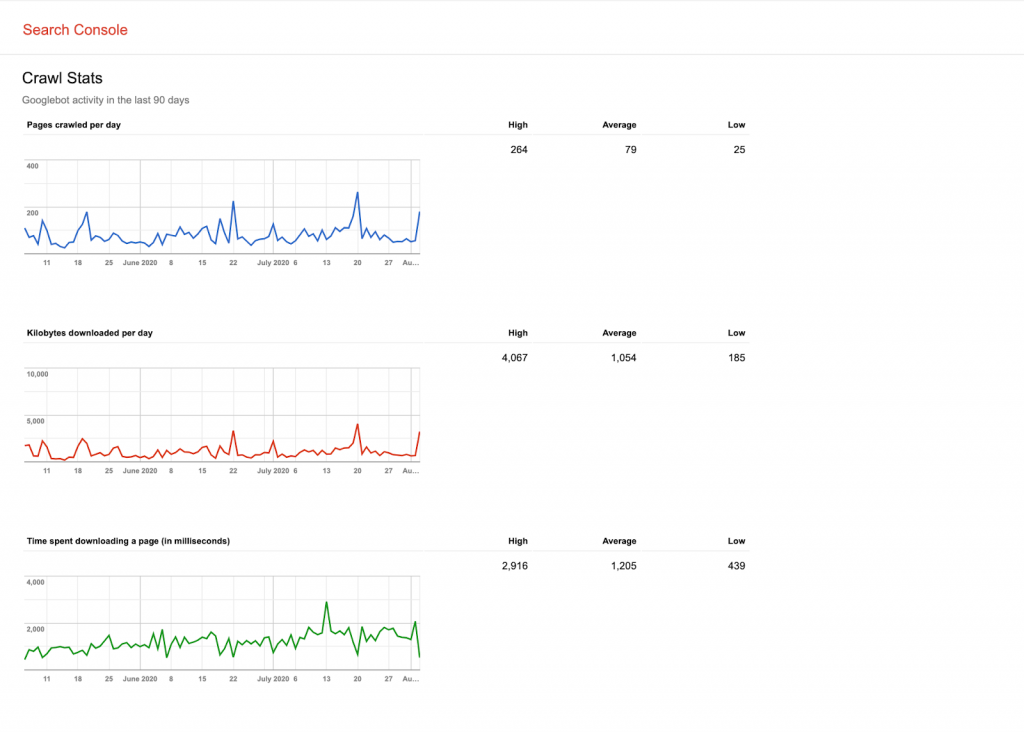
Bước 2: Truy cập báo cáo Thống kê thu thập dữ liệu và nhận ý tưởng về hoạt động của Googlebot trong 90 ngày qua.
Nhật ký máy chủ
Nhật ký máy chủ (Server Logs) lưu trữ mọi yêu cầu được gửi đến máy chủ web của bạn.
Mục nhật ký được thêm vào tệp nhật ký truy cập mỗi khi người dùng hoặc Googlebot truy cập trang web của bạn.
Googlebot để lại một mục nhập trong tệp nhật ký truy cập của bạn khi nó truy cập trang web của bạn.
Bạn có thể phân tích thủ công. Hoặc tự động tệp nhật ký này để xem tần suất Googlebot đến trang web của bạn.
Có những công cụ phân tích Commercial blog có thể làm điều này. Chúng giúp bạn có được thông tin liên quan về những gì Google bot đang làm trên trang web của bạn.
Báo cáo phân tích nhật ký máy chủ sẽ hiển thị:
- Tần suất trang web của bạn được thu thập thông tin.
- Googlebot truy cập trang nào nhiều nhất.
- Những loại lỗi mà bot đã gặp phải.
Dưới đây là danh sách các công cụ phân tích nhật ký phổ biến nhất.
Trình phân tích tệp nhật ký SEMrush
Trình phân tích tệp nhật ký SEO của Screamingfrog
OnCrawl Log Analyzer

Botlog của Ryte
SEOlyzer

Cách Tối ưu hóa Ngân sách Thu thập dữ liệu
Bây giờ, tôi hy vọng bạn biết rằng việc tối ưu hóa ngân sách thu thập dữ liệu quan trọng hơn đối với các trang web lớn hơn .
- Ưu tiên Thu thập thông tin gì & Khi nào
Bạn nên luôn ưu tiên các trang cung cấp giá trị thực cho người dùng cuối của mình.
Đây là cách bạn có thể tìm thấy các URL đó bằng cách tích hợp dữ liệu từ Google Analytics và Search Console.
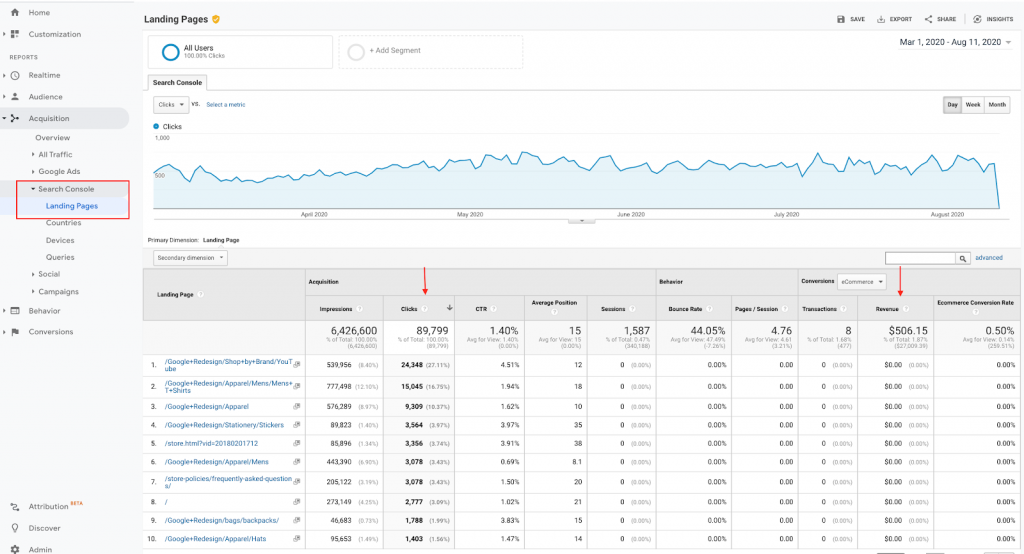
Các trang tạo nhấp chuột và doanh thu phải dễ dàng truy cập cho trình thu thập dữ liệu.
Đôi khi, bạn nên tạo một sơ đồ trang XML riêng lẻ bao gồm hoặc các trang chính của bạn
2. Xác định bao nhiêu tài nguyên mà máy chủ lưu trữ trang web có thể phân bổ
Tải xuống tệp nhật ký máy chủ của bạn và sử dụng một trong các công cụ được đề cập ở trên để xác định các mẫu và sự cố tiềm ẩn
Đây là ví dụ về Trình phân tích tệp nhật ký SEMrush
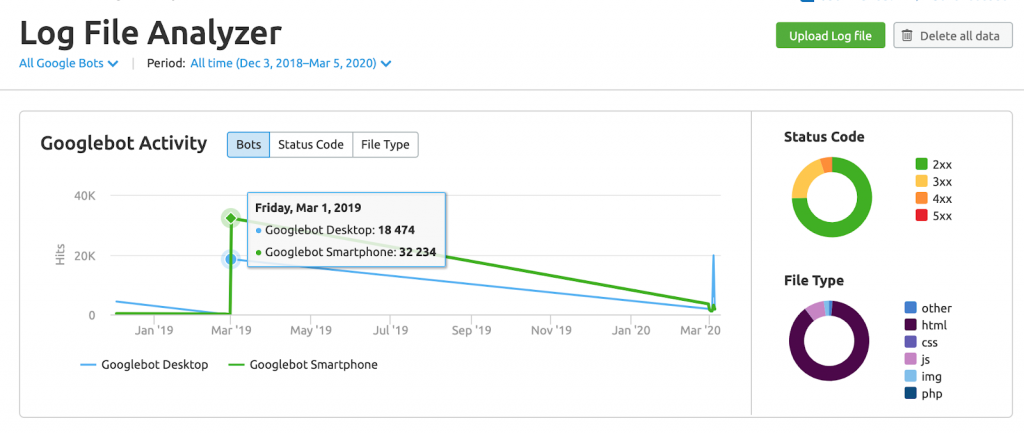
Mục tiêu cuối cùng của bạn ở đây là có được ý tưởng về cách Googlebot tác động đến thiết lập máy chủ hiện tại của bạn.
3. Tối ưu hóa các trang của bạn
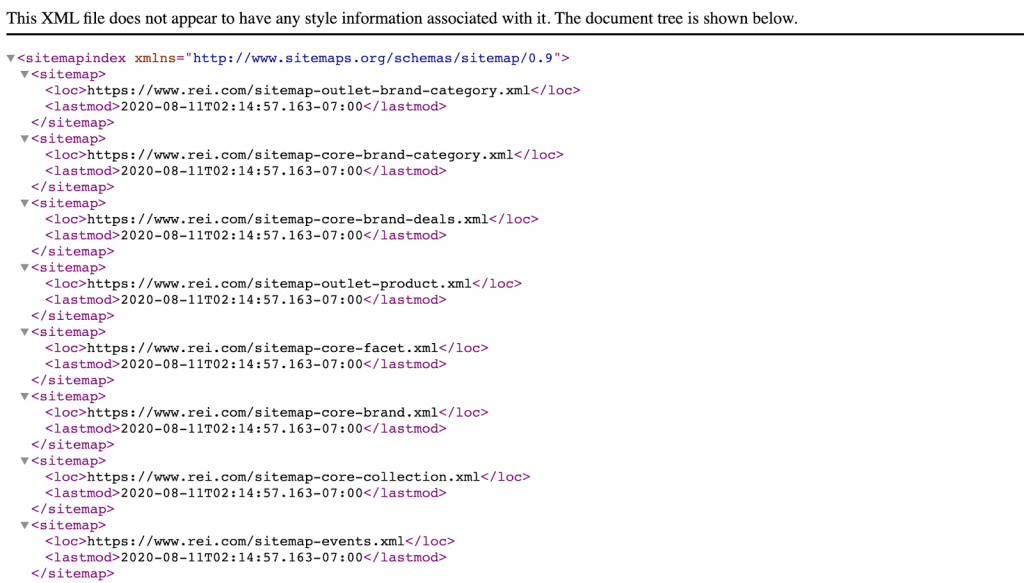
Tối ưu hóa Sơ đồ trang web XML
Tạo nhiều sơ đồ trang web được phân loại theo loại URL hoặc phần trong trang web của bạn (ví dụ: products.xml, blog-post.xml, v.v.).
Điều này sẽ giúp bạn kiểm soát quá trình Crawl đến các phần giá trị trên trang web của bạn.
Tần suất cập nhật
Đảm bảo rằng bạn thông báo cho Google mỗi khi nội dung của bạn được cập nhật.
Bạn có thể thực hiện việc này thông qua dữ liệu có cấu trúc. Sơ đồ trang web XML hoặc thậm chí là thẻ eTag .
Nội dung chất lượng thấp, nội dung spam & trùng lặp
Dọn dẹp trang web của bạn bằng cách loại bỏ chất lượng thấp, nội dung trùng lặp và / hoặc spam.
Sự cố liên kết
Các liên kết từ trang này sang trang khác vẫn cực kỳ quan trọng đối với quá trình crawl,
Mọi trang web nên sửa chữa định kỳ những thứ như chuyển hướng sai , lỗi 404 và chuỗi chuyển hướng .
Tối ưu hóa Robots.txt
Bạn có thể tối ưu hóa tệp robots.txt của mình bằng cách loại trừ các URL hoặc tệp không có giá trị khỏi quá trình thu thập thông tin.
Không loại trừ các nguồn hữu ích hoặc quan trọng từ Googlebot.
Quá trình thu thập dữ liệu đã thay đổi như thế nào?
Google và quá trình thu thập dữ liệu đã phát triển theo thời gian.
Dưới đây là tổng quan về những thay đổi quan trọng nhất trong vài năm qua.
Lập chỉ mục ưu tiên trên thiết bị di động
Vào tháng 3 năm 2018. Google bắt đầu ưu tiên nội dung di động trên web và cập nhật chỉ mục của mình từ ưu tiên máy tính để bàn thành ưu tiên thiết bị di động trong nỗ lực cải thiện trải nghiệm của người dùng trên thiết bị di động.
Với sự thay đổi này, Desktop Bot của Google đã được thay thế bằng. Googlebot trên điện thoại thông minh làm trình thu thập dữ liệu chính.
Ban đầu, Google thông báo rằng họ sẽ chuyển sang lập chỉ mục ưu tiên thiết bị di động cho tất cả các trang web bắt đầu từ tháng 9 năm 2020.
Ngày này đã bị trì hoãn đến tháng 3 năm 2021 do một số vấn đề .
Khi quá trình chuyển đổi hoàn tất. Hầu hết quá trình thu thập dữ liệu tìm kiếm sẽ do tác nhân người dùng điện thoại thông minh di động của Google thực hiện.
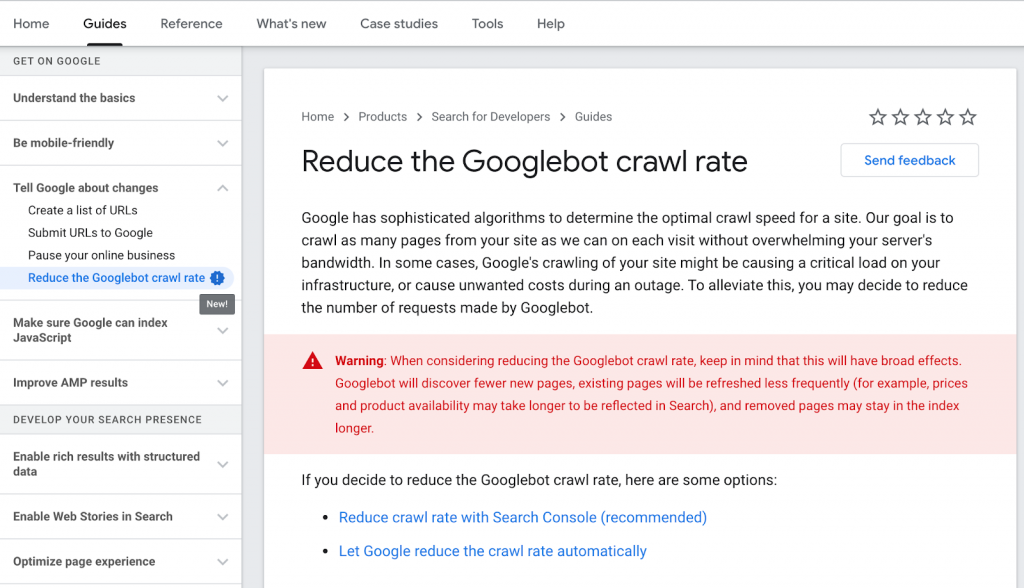
Giảm tỷ lệ thu thập thông tin của Googlebot
Google cho phép giảm tốc độ Crawl đối với các trang web gặp sự cố máy chủ nghiêm trọng. Hoặc chi phí không mong muốn trong quá trình thu thập thông tin.
Có một hướng dẫn mới về tài liệu dành cho Nhà phát triển của họ .
Lợi ích tương lai của việc thu thập dữ liệu
Như Kevin Indig đã chỉ ra . Có những dấu hiệu cho thấy sự thay đổi tiềm năng về cách. Google truy cập nội dung web từ thu thập dữ liệu sang lập chỉ mục API.
Từ Mobile-First đến AI-First
Vào năm 2017, CEO Sundar Pichai của. Google đã công bố chuyển đổi từ tìm kiếm và tổ chức thông tin của thế giới sang AI và học máy(machine learning).
Quá trình chuyển đổi này sẽ được thực hiện trên tất cả các sản phẩm và nền tảng
Google Tìm kiếm hiện đang sử dụng các loại học máy khác nhau (tức là BERT ) . Để hỗ trợ và cải thiện hiểu biết về ngôn ngữ con người, thuật toán xếp hạng và các trang kết quả tìm kiếm.
Đầu tư nhiều vào học máy và các chương trình AI sẽ cho phép Google có được mô hình dự đoán tốt hơn cho các trang kết quả tìm kiếm được cá nhân hóa cao.
Với mô hình dự đoán chính xác có thể xếp hạng trang web dựa trên nhiều điểm dữ liệu. (ví dụ: vị trí, lịch sử tìm kiếm, lượt thích,đối tượng, v.v.). quy trình thu thập dữ liệu hiện tại sẽ trở nên thừa vì công cụ tìm kiếm có thể cung cấp kết quả tốt với một đầu vào hạn chế.
Nói cách khác, Google sẽ không cần phải thu thập dữ liệu toàn bộ web . Chỉ những trang web có liên quan cho người dùng của mình.
Ngày càng khó thu thập thông tin web
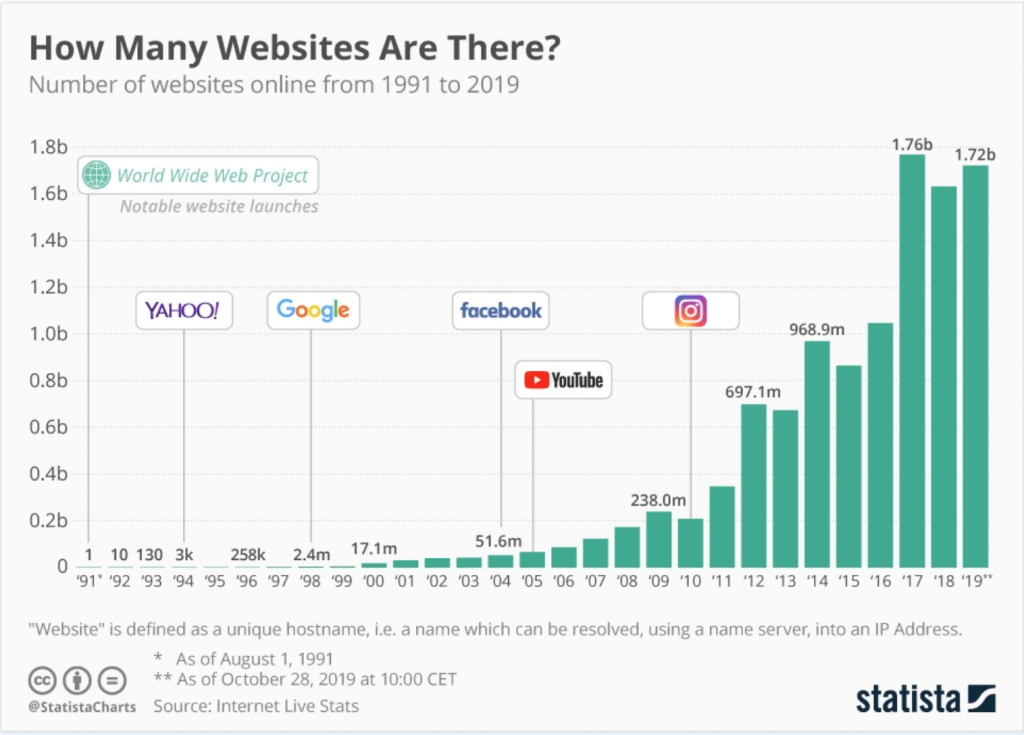
Với gần 2 tỷ trang web trên website. Việc thu thập dữ liệu và lập chỉ mục nội dung đã trở thành một quá trình đầy thử thách Và tốn kém đối với Google.
Nếu web tiếp tục phát triển với tốc độ này. Google sẽ dễ dàng hơn khi chỉ kiểm soát quá trình lập chỉ mục và xếp hạng tìm kiếm.
Từ chối các trang spam hoặc chất lượng thấp mà không lãng phí tài nguyên khi thu thập dữ liệu. Hàng triệu trang Google sẽ cải thiện đáng kể hoạt động của mình.
Trong tương lai, Google có thể cần giảm kích thước chỉ mục của mình để ưu tiên chất lượng. Và đảm bảo kết quả của nó có liên quan và hữu ích.
Cả Google và Bing đều có API lập chỉ mục
Cả hai công ty đều đã phát triển các công cụ mà bạn có thể sử dụng. Để thông báo cho họ bất cứ khi nào trang web của bạn được cập nhật.
Các API lập chỉ mục nhằm cung cấp thu thập thông tin, lập chỉ mục. Và khám phá nội dung trang web của bạn ngay lập tức.
Kết luận
Ngân sách thu thập dữ liệu – như một khái niệm và chỉ số tối ưu hóa tiềm năng thì nó có liên quan và hữu ích cho một loại trang web cụ thể.
Trong tương lai gần, ý tưởng về ngân sách thu thập dữ liệu có thể thay đổi. Hoặc thậm chí biến mất khi Google không ngừng phát triển và thử nghiệm các giải pháp mới cho người dùng của mình.
Bám sát các nguyên tắc cơ bản và ưu tiên các hoạt động tạo ra giá trị cho người dùng tiềm năng của bạn.
Trên đây là tất cả những kiến thức về Crawl Budget được tổng hợp từ kinh nghiệm của eFox Solution và từ nhiều nguồn khác nhau với mong muốn đem đến cho bạn những kiến thức hữu ích nhất. Qua bài viết này chúng tôi hy vọng rằng bạn sẽ có cái nhìn tổng quan hơn cũng như tầm quan trọng của Ngân sách thu thập dữ liệu trong công việc của bạn. Đừng bỏ qua bất cứ chỉ dẫn hữu ích nào nhé!
Nếu bạn thấy bài viết hay và hữu ích đừng quên chia sẻ cho mọi người.
Đừng bỏ qua dịch vụ SEO tốt nhất và bài viết hữu ích về SEO của chúng tôi.
Có thể bạn quan tâm: